Pourquoi certaines productions culturelles survivent-elles jusqu'à aujourd'hui alors que d'autres ont été perdues ? LostMa vise à comprendre comment les cultures humaines se constituent et évoluent, à travers la question de la transmission des artefacts écrits. Il se concentre principalement sur la littérature chevaleresque médiévale en Europe, et mêle les sciences de la complexité, l'intelligence artificielle et l'expertise philologique.
Présentation
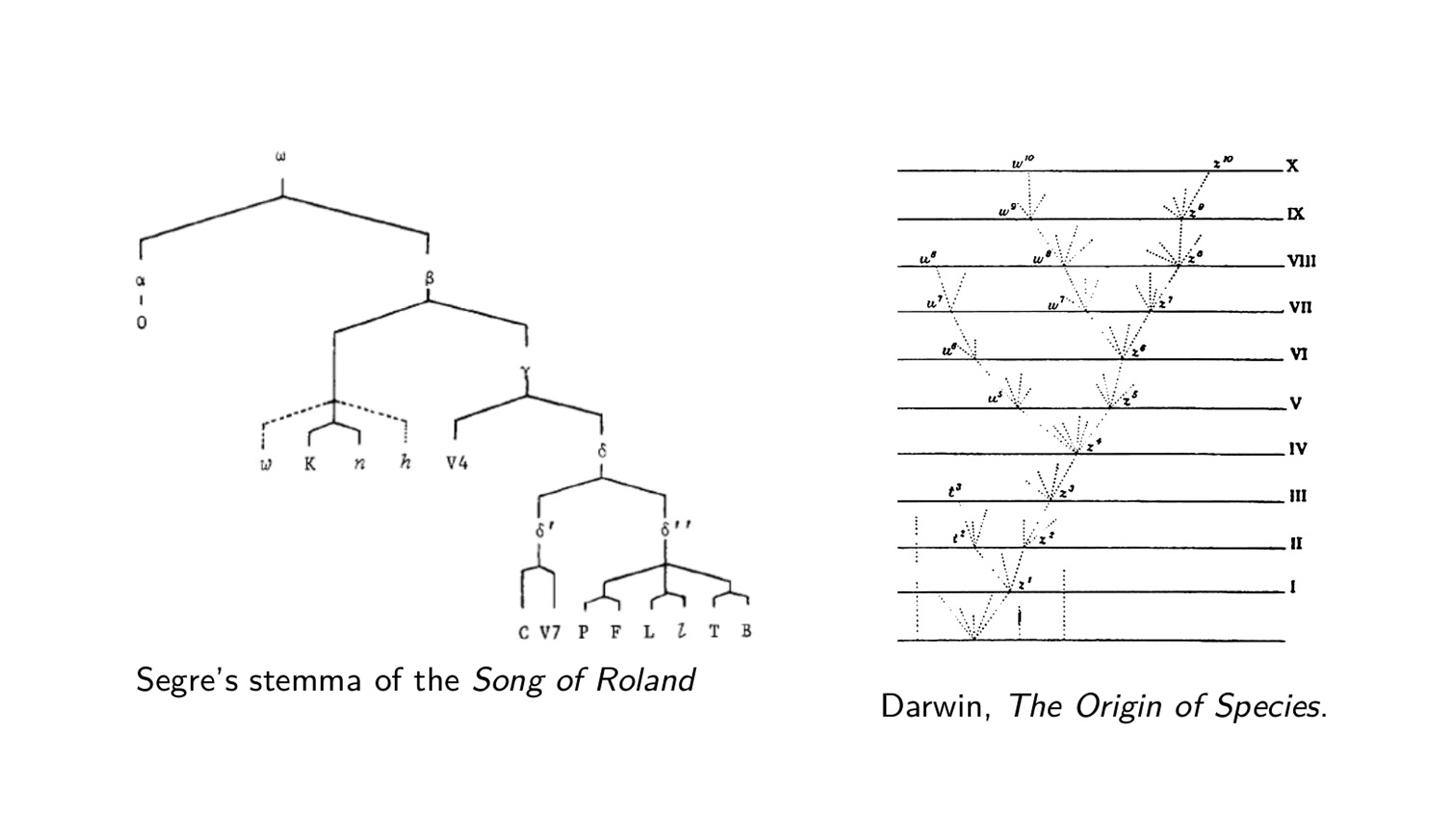
LostMa vise à comprendre comment les cultures humaines se constituent et évoluent, à travers la question de la transmission des artefacts culturels écrits. Ce projet s'efforce d'établir dans quelle mesure la transmission (et la préservation ou la perte subséquente) d'artefacts, de textes et d'idées écrits s'écarte du hasard et, si elle s'en écarte, dans quelle mesure et pourquoi. Pour ce faire, LostMa analysera la manière dont les textes manuscrits ont été copiés, transformés ou détruits, à l'instar de l'évolution des organismes vivants ou des variantes linguistiques, par le biais de processus d'innovation/mutation, de fixation ou d'extinction.
Ainsi, l'objectif de ce projet n'est pas seulement de comprendre les processus de transmission des textes, mais aussi de saisir dans quelle mesure les humains sont les acteurs de la transmission de leur propre culture et dans quelle mesure la survie des textes ou la constitution des canons culturels sont dus au hasard.
Si cette notion peut sembler provocante pour les chercheurs en sciences humaines, les biologistes évolutionnistes ont depuis longtemps découvert le rôle de la dérive aléatoire dans la survie ou l'extinction des traits génétiques et des espèces.
Pour étudier cette question, ce projet tentera un changement de paradigme dans les méthodes philologiques, en combinant l'intelligence artificielle, la science de la complexité et l'expertise philologique. Des processus stochastiques de naissance et de mort et des simulations informatiques multi-agents seront utilisés pour simuler le processus de transmission textuelle.
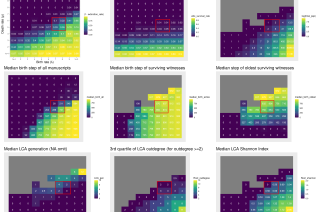
L'étude de cas concernera la littérature chevaleresque dans le contexte européen. Soutenue par des méthodes d'apprentissage profond, une collecte de données à grande échelle sera effectuée sur un corpus de 4000 documents en langues romanes, germaniques et celtiques, avec un zoom sur le texte intégral d'environ 1000 manuscrits en vieux français. Les données fourniront des valeurs observables à comparer aux résultats de simulation, afin de mesurer les écarts par rapport au hasard, de faire des déductions sur des valeurs non observables telles que les taux de perte/survie des œuvres et des manuscrits, et de comprendre les dynamiques à l'œuvre derrière la transmission des textes.
Financement
Le projet est financé par le Conseil européen de la recherche (ERC).
1 499 235 €
sur 4 ans
6 contrats
1 responsable scientifique, 1 postdoctorant, 2 ingénieurs de recherche, 2 doctorants
Vidéo
Les manuscrits perdus de l’Europe médiévale
Publication
Lost Manuscripts and Extinct Texts : A Dynamic Model of Cultural Transmission
Publication de chercheur
Communication dans un congrès
- Date de parution : 2022

Évènements

Référent(s) école
Jean-Baptiste Camps
Maître de conférences et responsable scientifique de l’ERC LostMa

Actualités
Le projet LostMA lauréat de l’appel du Conseil Européen de la Recherche (ERC)
Actualité
Publié le 04/09/2023